Slack에서 클라우드 인프라를 대화하듯 분석하는 CloudOps Assistant, 이렇게 만들어졌어요
일단 어떤 걸 만들었나
Slack에서 자연어로 인프라를 묻고 답을 받을 수 있는 에이전트를 만들어봤어요.
예를 들면 이런 식이에요.
"이번 주 비용이 가장 많이 증가한 ECS 서비스 보여줘"
"외부에 public access 가능한 리소스 찾아줘"
 agent-teaser.png
agent-teaser.png
만들고 싶었던 이유는 단순했어요. 클라우드 리소스를 파악할때 이미 인지하고 있는 구조라면 쉬운 얘기겠지만 리소스의 연결과 상호관계가 크면 클수록 콘솔에서 긴 시간을 보내야 한다는 점 때문이에요.
간단한 확인 하나에도 어느 계정에서 만든 리소스였는지 다시 찾아야 하고, 비용이 늘어난 원인을 추적하려면 여러 대시보드를 오가야 하고, 외부에 공개된 리소스가 있는지 점검하려면 또 다른 콘솔을 열어야 하죠. 콘솔을 5~6개 오가는 건 일상이에요.
더 까다로운 건 사용자마다 접근 가능한 범위가 다르다는 점이에요. DevOps나 운영팀이 아닌 팀원에겐 어디서부터 봐야 하는지조차 진입 장벽이 되는 경우가 많아요.
그래서 "각자의 권한 범위 안에서, Slack 한 줄로 답을 줄 수는 없을까" 이게 출발점이었습니다.
막상 만들어보니 기능 자체보다 권한과 실행 흐름을 다루는 일이 훨씬 어려웠고, 그 과정에서 마주친 문제와 풀어낸 방식을 정리해보려 해요.
처음엔 그냥 AWS MCP 연결로 시작했어요
처음엔 단순하게 시작했어요. AWS MCP를 그대로 붙여서 Slack에 봇을 연결해서 묻고 답을 받는 구조였죠.
AWS MCP를 고른 이유는 분명했어요. 클라우드 운영 질문은 대부분 여러 서비스를 횡단해서 답을 찾아야 하는 형태인데, AWS MCP는 그걸 풍부한 tool-call 단위로 이미 잘 정리해둔 상태였거든요. 직접 스킬을 짜서 풀려고 했다면 커버할 수 있는 질문 범위가 훨씬 좁아졌을 거예요. 어려운 질문까지 커버 가능한 capability ceiling이 결정적이었습니다.
제 계정 하나만 연결해서 테스트해보니 곧잘 동작했어요.
그런데 여러 사용자가 각자의 계정을 연결해 쓰는 상황을 가정해보기 시작하니까, 이 구조로는 안 되겠다 싶은 지점들이 보이기 시작했습니다.
크게 세 가지였습니다.
1. AWS MCP는 단일 세션 전제로 설계되어 있다
가장 먼저 부딪힌 건 MCP 자체의 설계 가정이었어요. AWS MCP는 하나의 자격증명으로 동작하는 걸 기본으로 두고 만들어져 있어요. 로컬에서 개인이 자기 IAM 자격증명을 붙여 쓰는 시나리오에는 잘 맞지만, 여러 사용자가 각자의 role을 연결해 쓰는 환경에서는 곧장 벽이었습니다.
각 사용자가 자기 클라우드에 연결해둔 role은 모두 달라요. 어떤 사용자는 dev 계정만, 어떤 사용자는 prod 계정까지, 어떤 사용자는 특정 region 안에서만 권한이 있죠. 하나의 MCP 인스턴스가 모든 사용자의 요청을 받는 구조에서는, 매 요청마다 누가 어떤 권한으로 요청한 건지를 격리해서 실행할 방법이 필요했습니다. (구체적으로 어떻게 풀었는지는 다음 섹션에서 다룰게요.)
2. inspection은 길어질 수밖에 없다
"이번 주 비용이 가장 많이 증가한 ECS 서비스 보여줘" 같은 질문 하나에도 여러 API 호출이 필요해요. 동기 처리로 가면 Slack 응답이 늦어지고 타임아웃에 걸리기도 했어요. 그 사이 사용자는 다른 질문을 또 던질 수도 있고요.
3. 한 번의 tool-call로는 답이 안 나오는 질문이 많다
"어제 RDS CPU spike 원인 분석해줘" 같은 질문은 metrics만 봐서는 답이 안 나와요. 로그를 같이 보고, 비슷한 시점의 이벤트를 찾고, 관련 리소스 상태도 확인해야 하죠. 다단계 분석을 어떻게 끌고 갈지가 또 다른 숙제였습니다.
이 네 가지를 들여다보면서 한 가지가 분명해졌어요.
LLM 자체보다, 권한과 실행 흐름을 다루는 일이 훨씬 어려웠다.
LLM은 이미 충분히 똑똑했어요. 문제는 그 똑똑함을 여러 사용자의 권한 경계 안에서, 끊기지 않는 운영 흐름으로 풀어주는 layer였습니다.
그래서 이렇게 다시 설계했어요
아키텍쳐 다이어그램
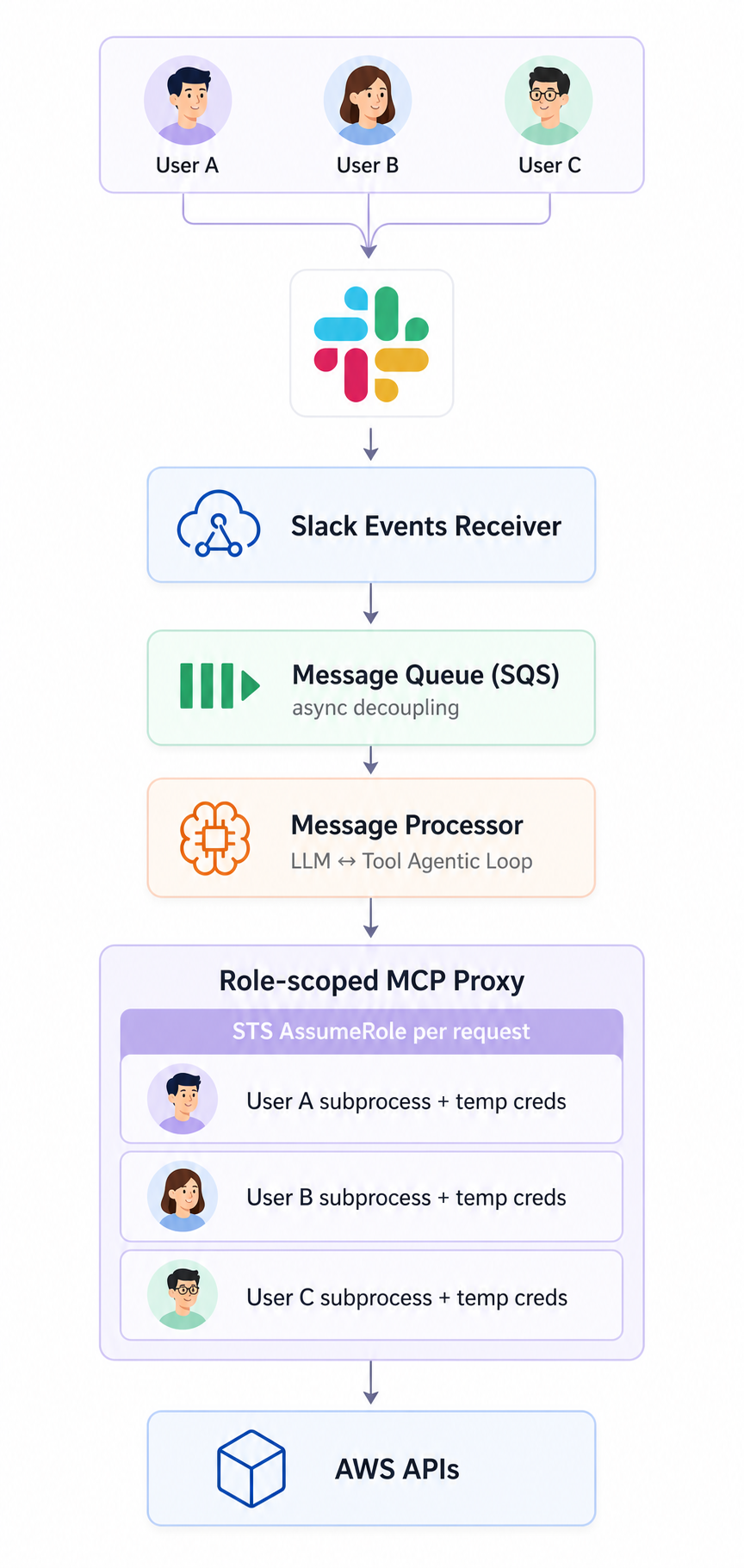 architecture-flow.png
architecture-flow.png
전체 구조는 위 다이어그램으로 정리해뒀어요. 2번에서 짚은 세 가지 문제에, 다이어그램의 세 블록이 거의 1:1로 대응됩니다. 어떤 의도로 그렇게 갈랐는지 순서대로 풀어볼게요.
1. 사용자별로 격리된 MCP Proxy로
AWS MCP가 하나의 자격증명으로 동작하도록 설계됐다는 점은 그대로 받아들이기로 했어요. 대신 그 위에 사용자별로 분리된 subprocess를 띄우는 방식으로 풀었습니다. MCP가 권장하는 stdio transport를 그대로 쓰되, 사용자마다 자기 자격증명이 주입된 subprocess가 따로 떠 있는 구조죠.
자격증명은 STS AssumeRole로 해당 사용자의 role을 가정해서 임시 자격증명을 발급받아 쓰는 방식이에요. 일정 시간이 지나면 알아서 만료되니까, 영구 키를 어딘가에 보관하지 않아도 되는 게 가장 큰 안심이었습니다.
이 구조로 간 결정적인 이유는 race condition 이었어요. 단일 프로세스에서 환경변수를 갈아끼우는 방식은 동시 요청이 들어올 때 사용자 A가 사용자 B의 자격증명으로 AWS를 호출하는 사고가 가능한 구조였고, OS 레벨에서 분리하는 것 말고는 안전한 길이 없었습니다.
그 위에 작은 최적화 하나를 더 얹었어요. 같은 사용자의 후속 요청은 매번 새 subprocess를 띄우지 않고 기존에 떠 있던 걸 재사용하도록 풀에 보관해두는 방식이에요. 덕분에 두 번째 요청부터는 콜드스타트가 사실상 없습니다.
2. 긴 inspection은 큐로 끊어내기
"이번 주 비용이 가장 많이 증가한 ECS" 같은 질문은 여러 AWS API를 호출하면서 시간이 꽤 걸려요. Slack은 빠른 응답을 기대하는 채널이라, 처리 자체와 응답 시점을 분리할 필요가 있었습니다.
사이에 SQS 큐를 한 단계 두는 걸로 풀었어요. Slack 이벤트는 받는 즉시 큐로 흘려보내고, 처리는 별도 컨슈머가 자기 페이스로 끌고 가는 구조예요. 길게 도는 분석이 다른 사용자의 응답을 막거나, Slack 타임아웃에 걸리는 일을 피할 수 있게 됐어요.
3. 한 번의 호출로는 답이 안 나오는 질문, 반복으로 풀기
"어제 RDS CPU spike 원인 분석해줘" 같은 질문은 metrics 한 번 보고 끝낼 수 없어요. 메트릭을 보고, 비슷한 시점에 이벤트가 있었는지 확인하고, 관련 리소스 상태도 같이 봐야 답이 모이는 식이에요.
그래서 LLM과 tool 호출을 루프로 묶었어요. 의사코드로 간단한게 적용할 수 있었어요.
while (LLM이 더 봐야겠다고 하면) {
다음 tool 호출 → 결과를 다시 LLM에
}
이 루프가 끝나는 시점은 LLM 스스로 충분히 봤다고 판단할 때예요. 사람이 이 정도면 결론 나왔네 하고 화면 닫는 순간과 비슷한 셈이죠.
세 가지를 다 정리하고 보니, AI agent 기능 이라기보다는 여러 사용자의 권한과 실행 흐름을 다루는 운영 layer 에 가까운 형태가 되어 있었어요.
다음 섹션에서는 이 구조 위에서 어떤 질문에 어떻게 답이 나오는지, 몇 가지 패턴만 짚어볼게요.
그래서 어떤 질문에 어떻게 답하는가
1. 비용
"이번 주 비용이 가장 많이 증가한 ECS 서비스 보여줘"
평소라면 비용 대시보드 열어서 cluster 단위로 들여다보고, 의심 가는 서비스를 하나씩 비교해야 했을 거예요. 프롬프트 한 줄이 서비스별, 원인, 해결방법에 대한 제시를 해줘요.
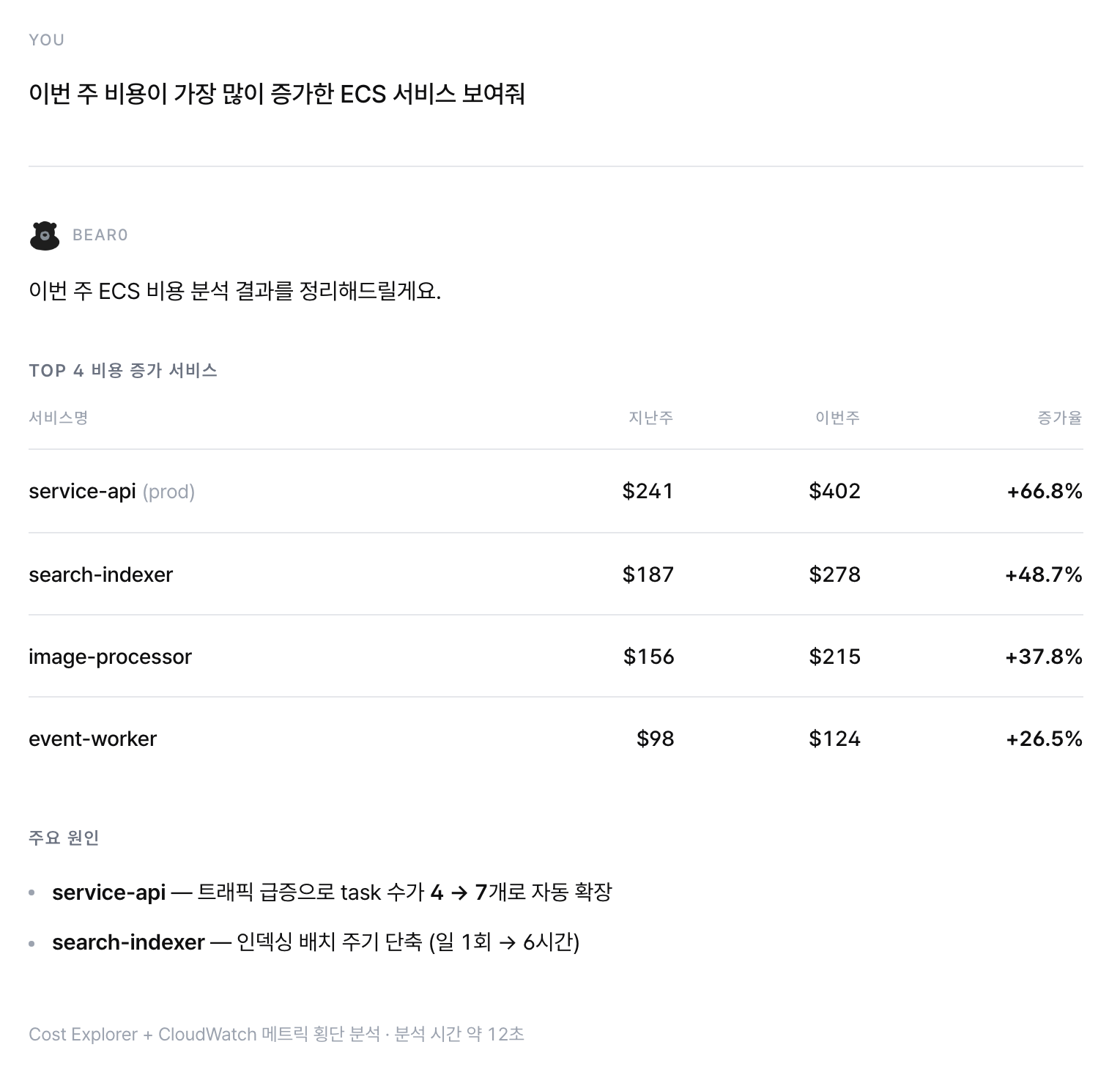 example-cost.png
example-cost.png
2. 보안
"public access 가능한 리소스 찾아줘"
손에 익은 체크리스트가 있긴 한데 리소스 타입마다 "public 인지" 판정하는 방법이 다르니까 매번 한참 걸리는 작업이에요. 그걸 "그냥 찾아줘" 한 줄로 묶을 수 있게 됐습니다.
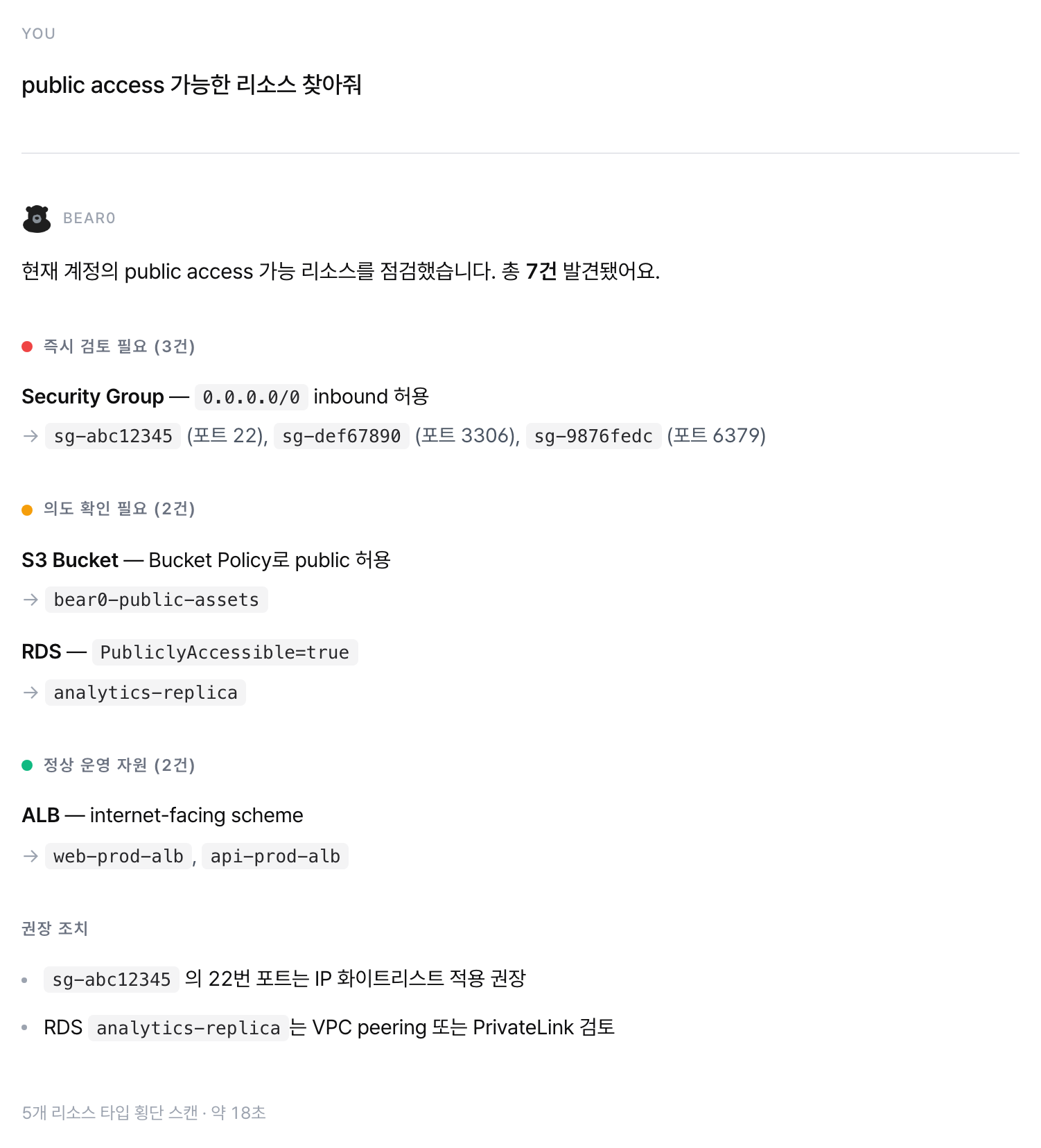 example-security.png
example-security.png
3. 원인 분석
"어제 RDS CPU spike 원인 분석해줘"
평소엔 메트릭에서 spike 시점 찾고, 그 시간대의 로그·이벤트·관련 워크로드까지 따라가는 손이 많이 가는 분석이에요.
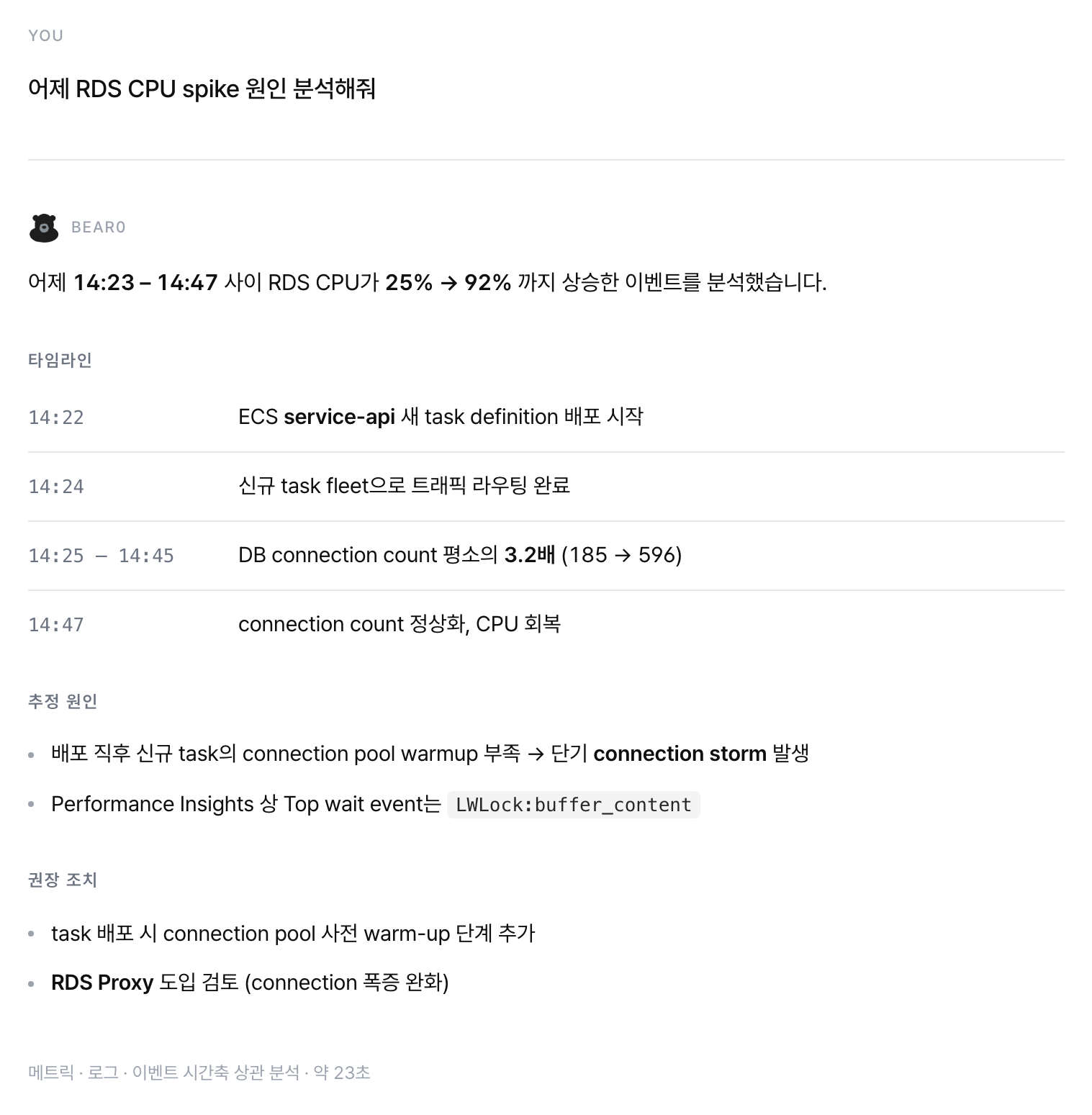 example-rootcause.png
example-rootcause.png
세 가지 모두 평소엔 콘솔 몇 개를 열어서 따라가야 했을 일들이에요. 1번에서 이야기한 콘솔을 옮겨다니는 일이 프롬프트 한 줄로 정리되는 게 사실 가장 와닿는 변화였습니다.
마무리
마지막으로, 지금 구조 위에서 다음에 해보고 싶은 것들을 짧게 정리하고 마치려고 해요.
사용자별 대화 메모리. 지금은 한 번의 질문 안에서만 단계 간 컨텍스트가 유지되고, 메시지 사이의 멀티턴은 아직 안 됩니다. "방금 본 그 ECS 더 자세히" 같은 후속 질문이 자연스럽게 동작하려면 다음 단계예요.
Audit / evidence trail. 프롬프트로 받은 답이 어떤 호출의 어떤 결과를 묶은 건지 추적 가능하게 만드는 일. 운영팀이 회의나 보고에 가져다 쓰려면 결국 증빙 까지 따라와야 합니다.
만들어보면서 가장 인상 깊었던 건 LLM 자체가 아니라, 권한과 실행 흐름을 다루는 layer 가 결국 사용자 경험을 결정한다는 점이었어요. 콘솔을 5-6개 오가던 일이 프롬프트 한 줄로 정리되는 건, 결국 그 layer 위에서 가능해진 거니까요.
CloudOps workflow가 대시보드 중심 에서 대화형 으로 옮겨갈 수 있겠다는 감각이 만들어보고 나서야 조금 더 분명해졌습니다.